The structure of the data as released and the interactive tool to visualise it are a mess of bad choices that get in the way of helping other analysts derive useful understanding from the data. They could do much better.
Every year the vestigial stump of number crunchers in NHSE who still brand their work as NHS Digital produce a report on the previous year's A&E performance.
The good thing is that the latest report releases far more data than has been normal in the past. There are many new breakdowns and extra pieces of data summarising what happened. And there is some interactive data visualisation. Unfortunately the effort to visualise the data screwed the pooch by being worse than useless.
There are some problems with the data as released as well but the big errors are in the choices made visualisting it. I could have some fun satirising the bad choices but, since I know that someone in NHSD reads at least some of the things I say, I want to provide some critical feedback on specific issues alongside some suggestions about how to do better in the hope that improvements can be made.
Some of the charts contain spectacularly bad choices of what to include
Take the original version of this chart which does contain some very interesting information:
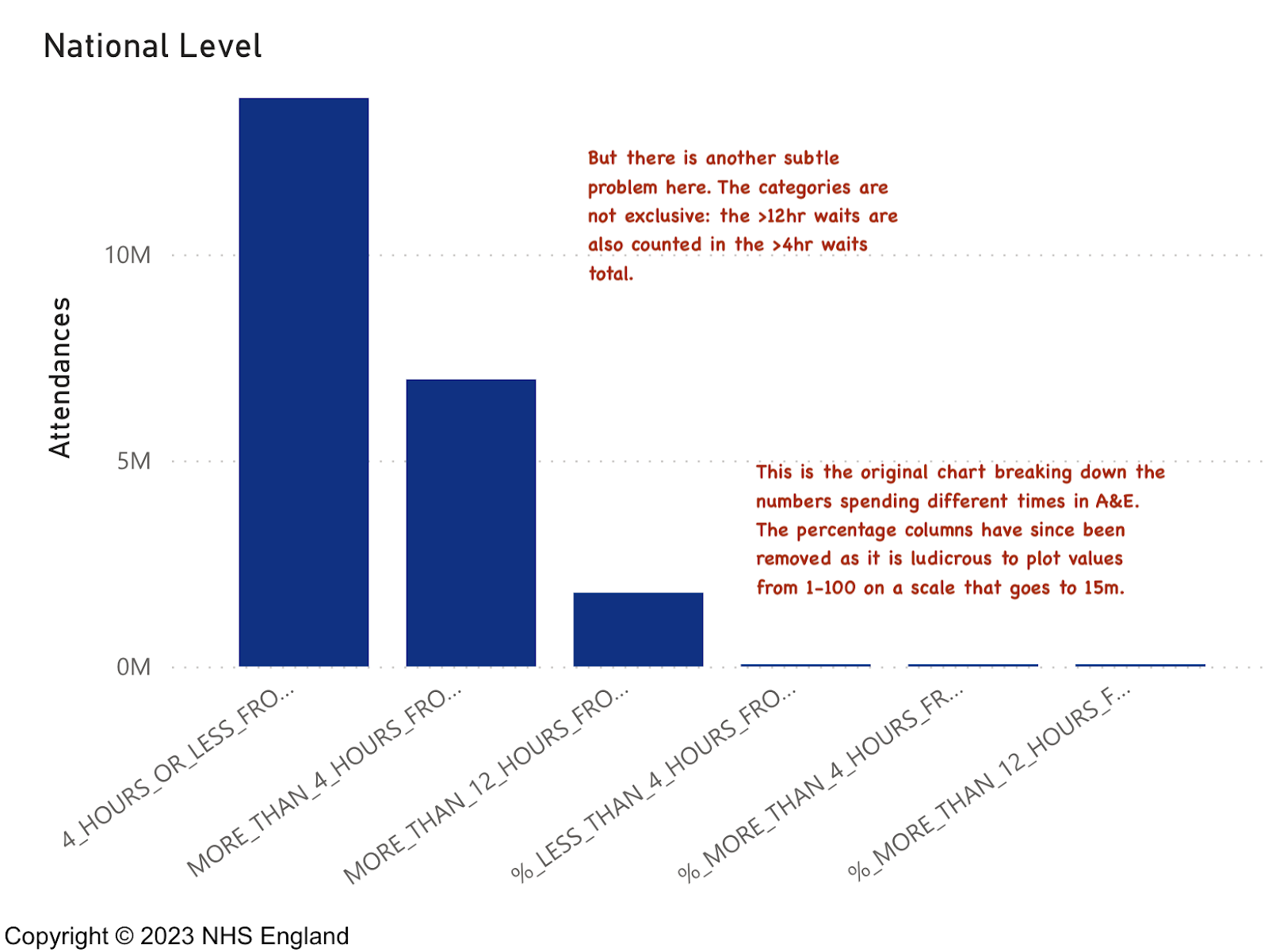
It is important to know how many patients waited >4hr (it is the key performance target) and how many waited >12hr. It is good to know the total number of patients waiting in each category and also the proportion of each as a percentage of total attendance. But the percentages (by definition numbers between 0 and 1 or 0 and 100 depending on how they are presented) are plotted on the same scale as attendance (a scale from 0 to about 15m). So, by plotting them on the same scale, the designer has guaranteed we can't see the percentages. In effect, presenting the data this way makes it impossible to see the key statistic any user needs to see. (and don't get me started on the unreadable diagonal labels: the designer could have truncated the names to be readable or rotated the chart 90° to make them horizontal and easier to read.)
To be fair, they partly fixed this chart (possibly because I pointed out the absurdity on Twitter).
I quote the original version of this example because it illustrates the problem across many of the visualisations on the site. It is as if the manager who demanded the data be visualised gave no guidance as to what was important and allowed some PowerBI developer to just dump the data into whatever default dataviz PowerBI chose without any consideration of useability or relevance.
Doing this is a chronic waste of time for both the developer and the user. The result is to distract from the data rather than to highlight the important parts of it.
There is another, more subtle, problem with this chart: the plotted values are not, as the visualisation implies, separate. The total shown for the >12hr metric is also included in the >4hr metric. Were the metrics plotted in a simple table this might not be such a problem. But in a chart like this the visual implication is that they are independent.
Yes, we need to know those metrics, but the underlying information has other useful data about the distribution of waits. Unfortunately the data doesn't seem to contain the best way of showing the overall distribution of waits which can provide insight into the nature of the problem in a hospital's processes.
To illustrate what could have been done here are some old charts displaying more complete data on the distribution of waits (which is present in the source ECDS data). These are based on some work first done around 2010 by some A&E experts to better understand the differences between hospitals, but which are also useful inside a single department to highlight certain common issues.
The A&E Tzar in 2010 thought that a typology of the shape of charts like this could identify a range of common performance problems and do so early so breaches of the major targets could be corrected before they happened.
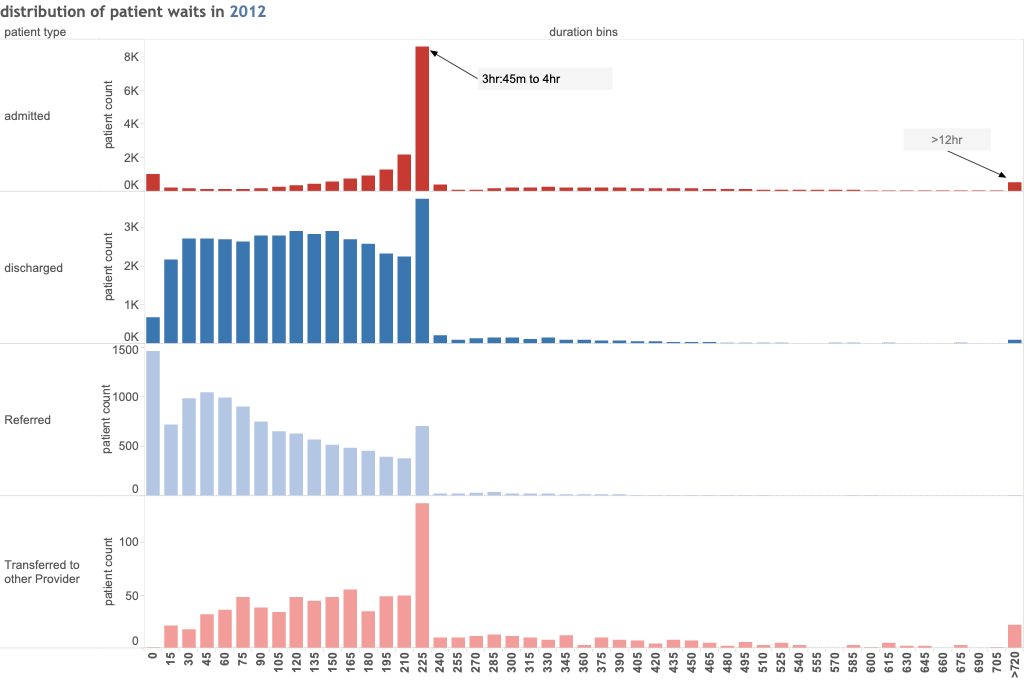
This type of chart (in this case from a poor performer in 2012) illustrate how a simple comparison of the distribution of waiting times can provide some insight. The basic chart shows the number or proportion of patients waiting for different times. Each column is a 15min block of waiting times and shows the proportion who departed with a wait of that length. Patients types are shown separately to highlight the stark difference in waits for different categories of patient. In this case there is clearly a much bigger problem with admitted patients tna for discharged patients. These patterns can signal the need to act even before the whole hospital breaches the 4hr target (what the shapes look like now nobody meets the target would be fascinating and informative).
Even the simple version of this chart (with no separation of patient categories) is still useful. Indeed, NHSD used to publish something similar for waiting times (if I remember correctly, they used 10min intervals, not the more natural 15min and grouped all >4hr waits together) but, unless I missed it, this is not available in the latest release. But all the data needed to reproduce my version of those charts is present in the original ECDS source and providing this sort of analysis of waits would have been a great service to all A&E analysts.
But NHSD didn't release this sort of chart nor the aggregate data needed to build it for each trust. If they had it would have been a major benefit for all who care about the data but don't have access to the raw patient level ECDS records to recreate it themselves.
Other charts have the same type of problem
But, since NHSD are responding to criticism, let me try to make some more suggestions about how to do better with the other charts.
So here is how the national level age structure of A&E attenders is presented. In this case there is also a chart where this data can be seen against the structure in a specific trust for comparison purposes. This is sometimes a useful comparison to make and it is certainly interesting to see the age structure of demand. So bonus points for knowing that this comparison is useful.
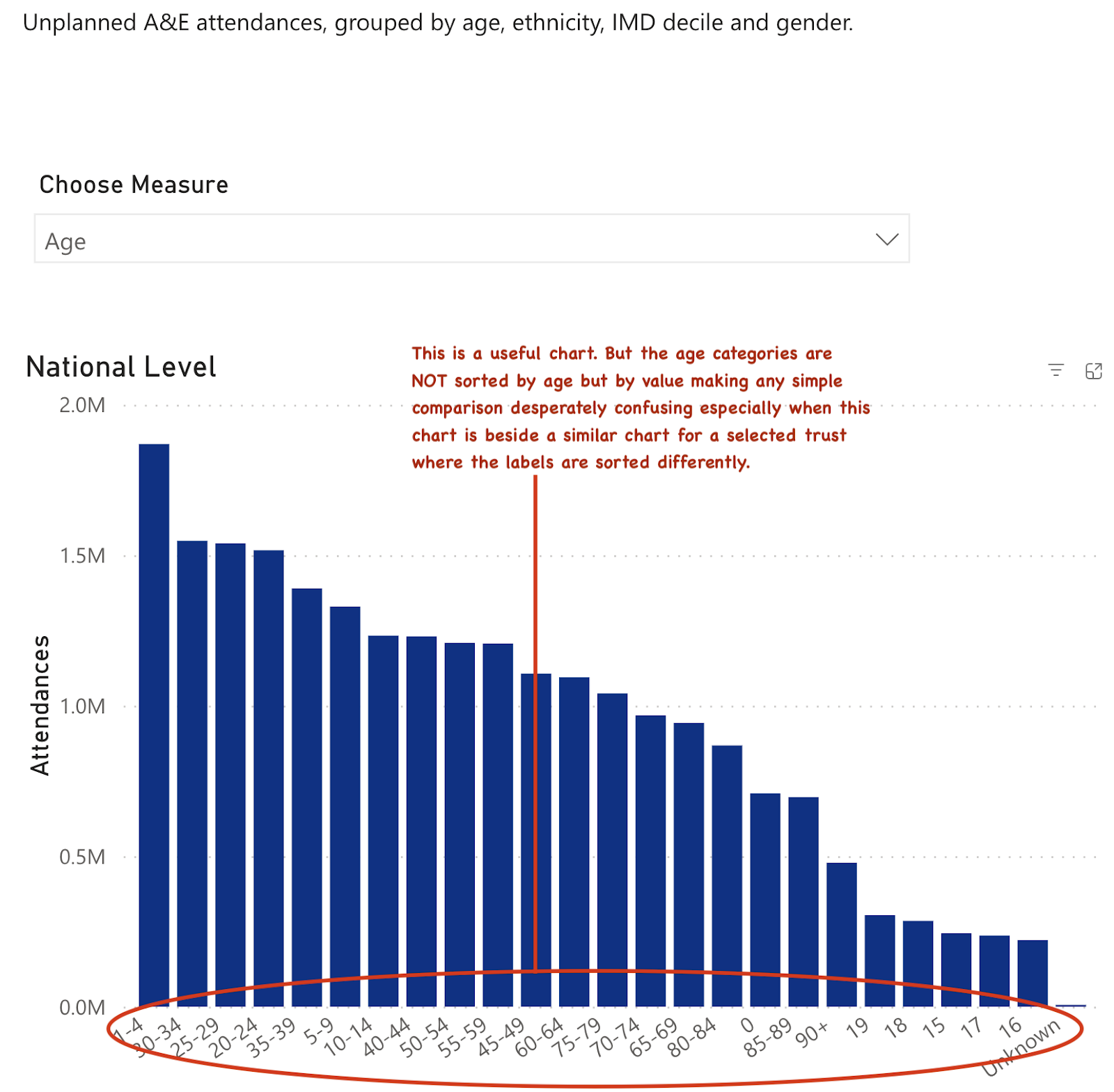
But there is a very basic problem with how the data is presented: the data isn't sorted by age (it seems to be sorted by the size of the attendance in each group, which is useless and arbitrary).
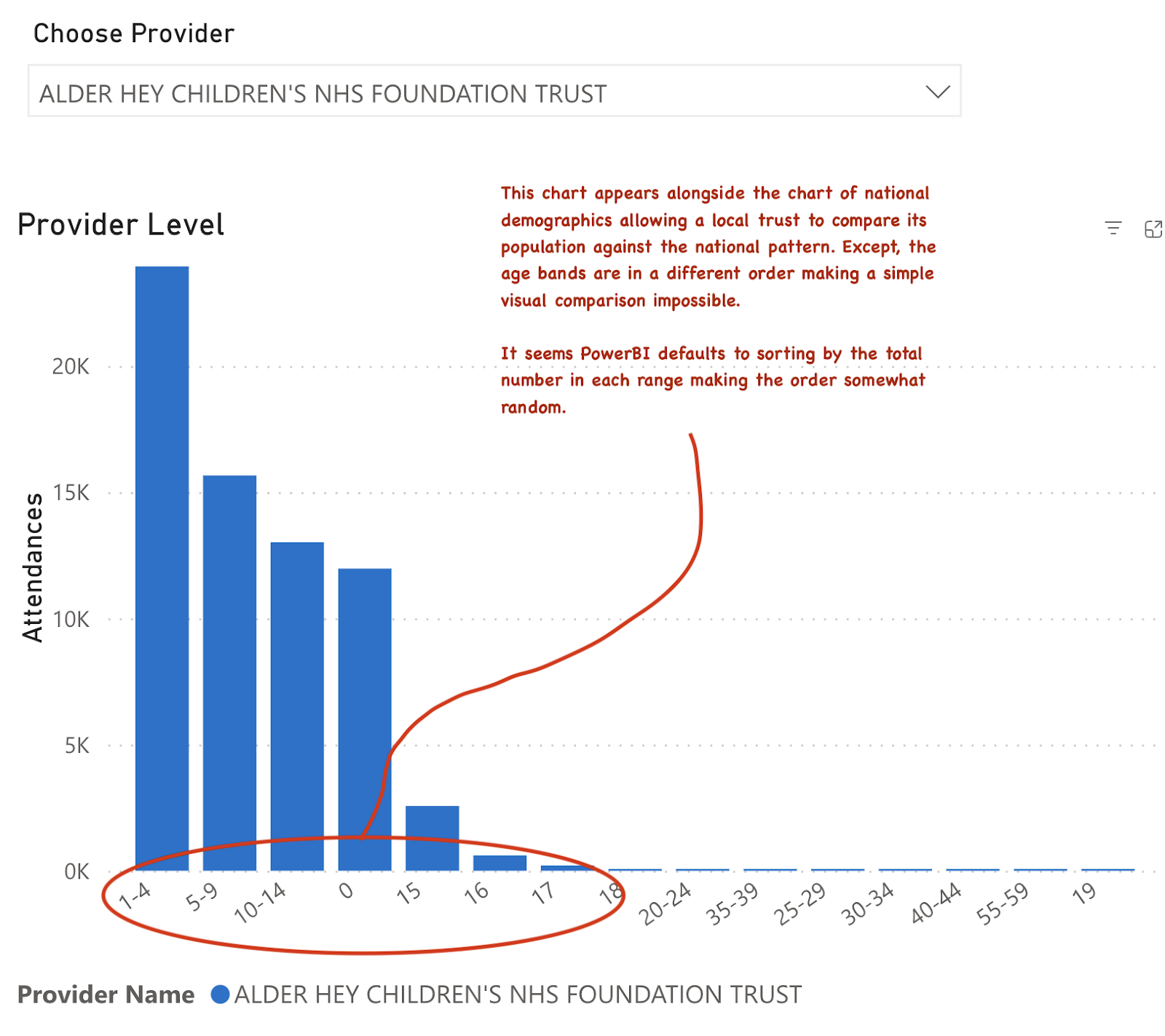
And the chart sits beside another chart of the demographics at a selected trust. But, since the sorting on the age groups is by volume not age, the scale is sorted differently. This makes any visual comparison of national versus local age distribution impossible. Anyone needing to see the comparison would need to completely redo the charts themselves from the raw data.
And there is a commonly used way to display information like this: the population pyramid. Here is an example from a different dataset:
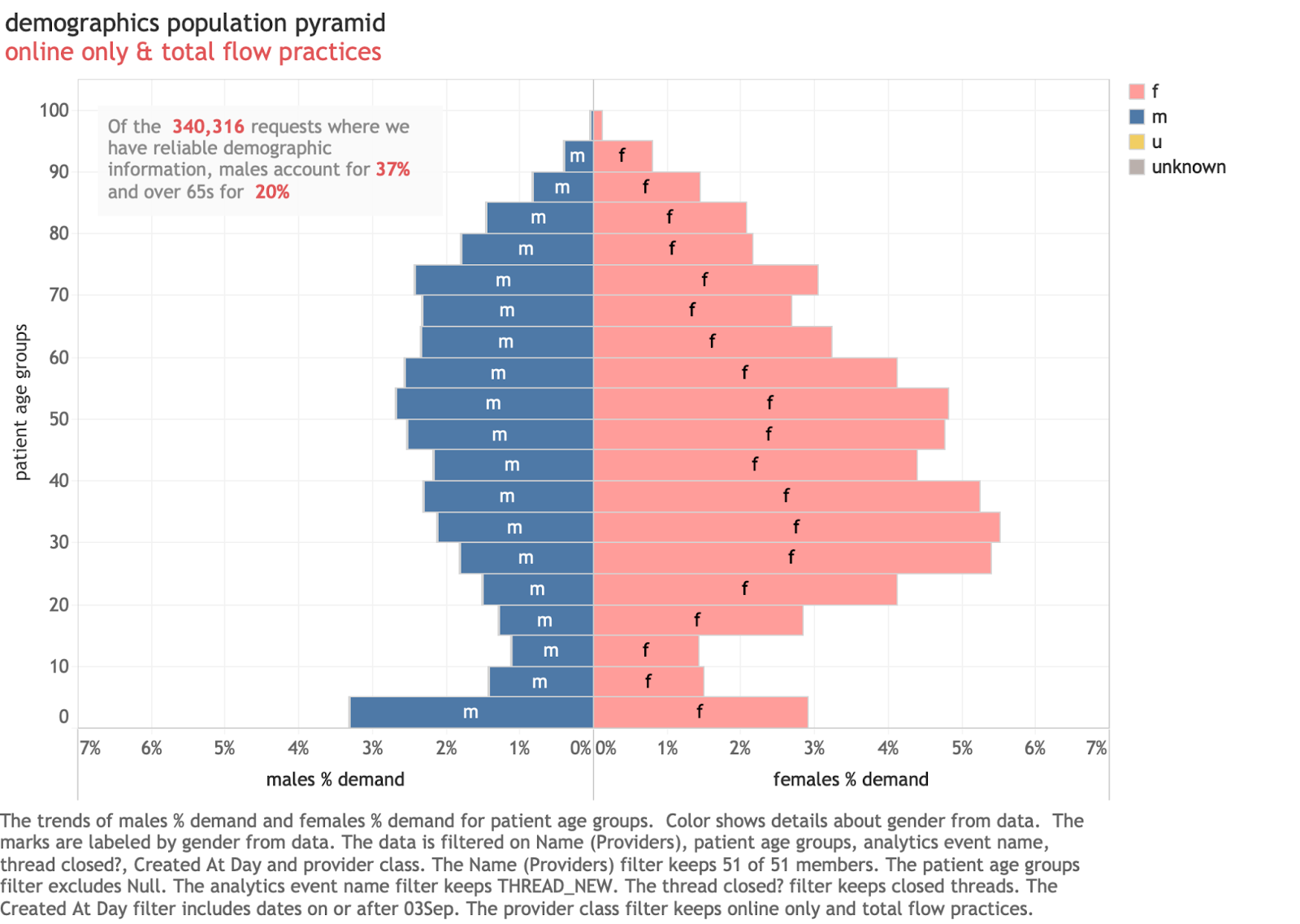
This is actually from a GP system and illustrates a familiar way to present population information. It has several features that can't be done with data from A&E systems as released by NHSD. The gender mix is useful to know (eg it is very clear here that more women use the service than men). The age bands are consistent sizes (5 years each) which makes interpreting the overall pattern easier. And they are sorted correctly by age which improves the consistency of the patterns.
This is the sort of chart demographers almost universally use for exploring population structures. The ONS website has interactive versions for exploring the UK population structure.
But we can’t do this with the A&E data. We can't compare by gender as the data in the A&E dataset contains gender but not gender linked to age bands. And the bands in the A&E data are inconsistent sizes in the data. Had the NHSD data been structured differently, a standard population pyramid would have been possible, but they seemed unaware of the utility of doing this and left age separated from gender in the data release.
But we could still do a sort of simple population pyramid from the A&E data as a visualisation. And one that makes comparisons across trusts easier. In the chart below the A&E data is plotted using only minor adjustments (age bands are grouped to a consistent 5-years and ordered properly).
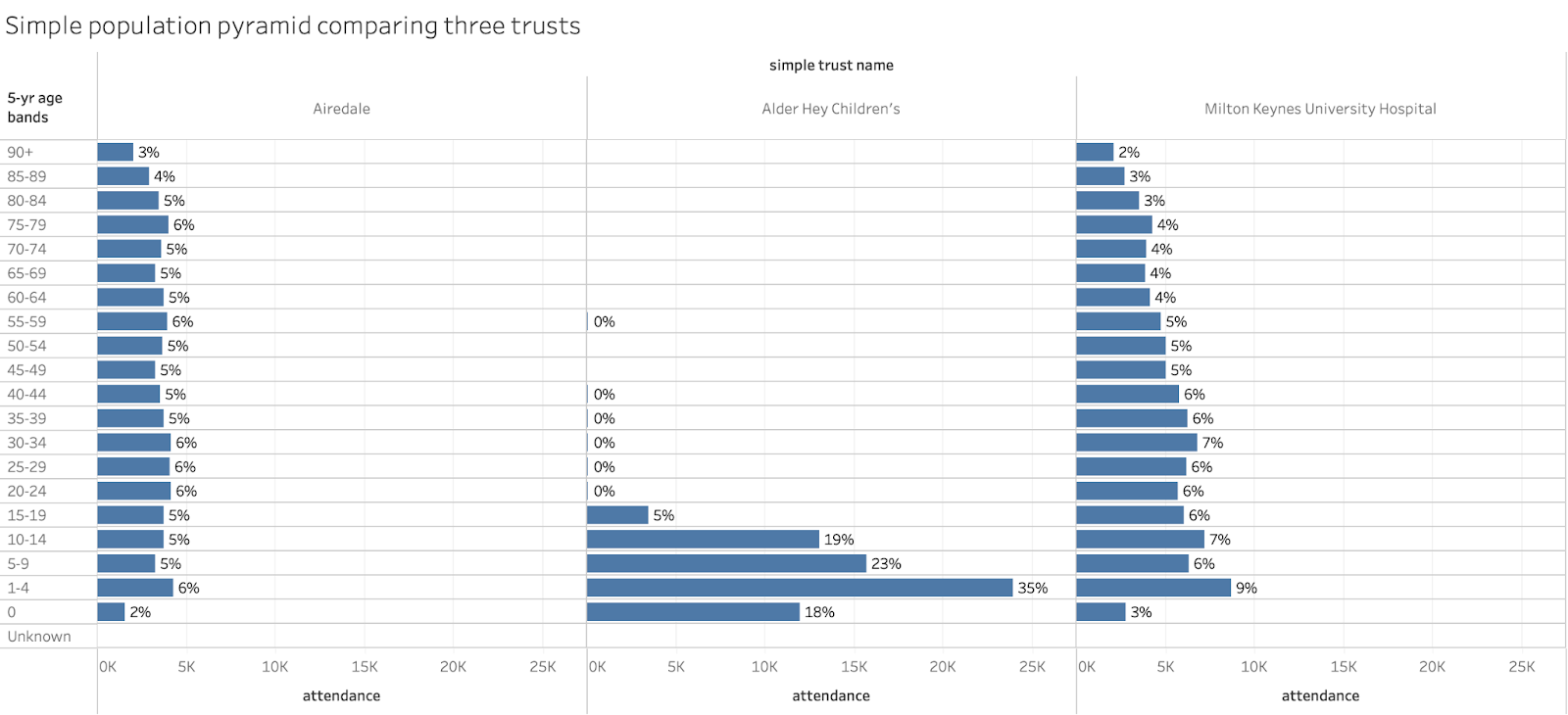
Were the linked data on gender present in the released spreadsheets, this could easily be converted to a more normal pyramid containing both the age and sex of the attendance.
Another useful thing to know is where the volume is coming from. The data on referral source is available. The chart for this is below:
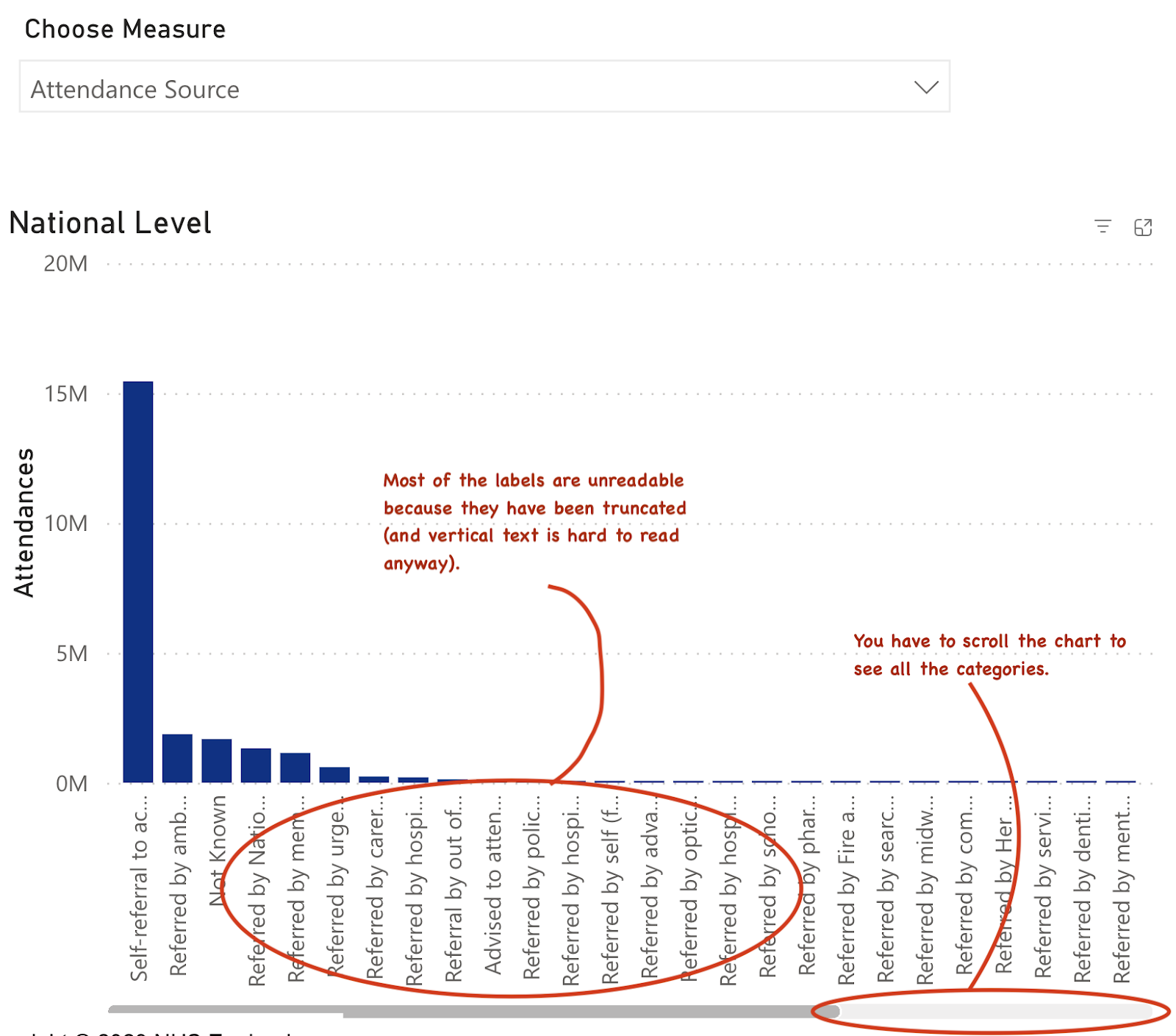
The biggest problem with this chart is the unreadable labels and the crowding which makes it hard to see all the data at once.
There is a better way to present this data that minimises those problems. The comparisons below use a treechart to visualise the data. This has some benefits: the visual comparison across trusts is accurate but, also, the biggest volume categories are the most visible, minimising the crowding of the chart by small or irrelevant categories with low volume. (in this case further work could highlight the major categories more effectively but this default chart already does a good job of highlighting major differences across trusts):
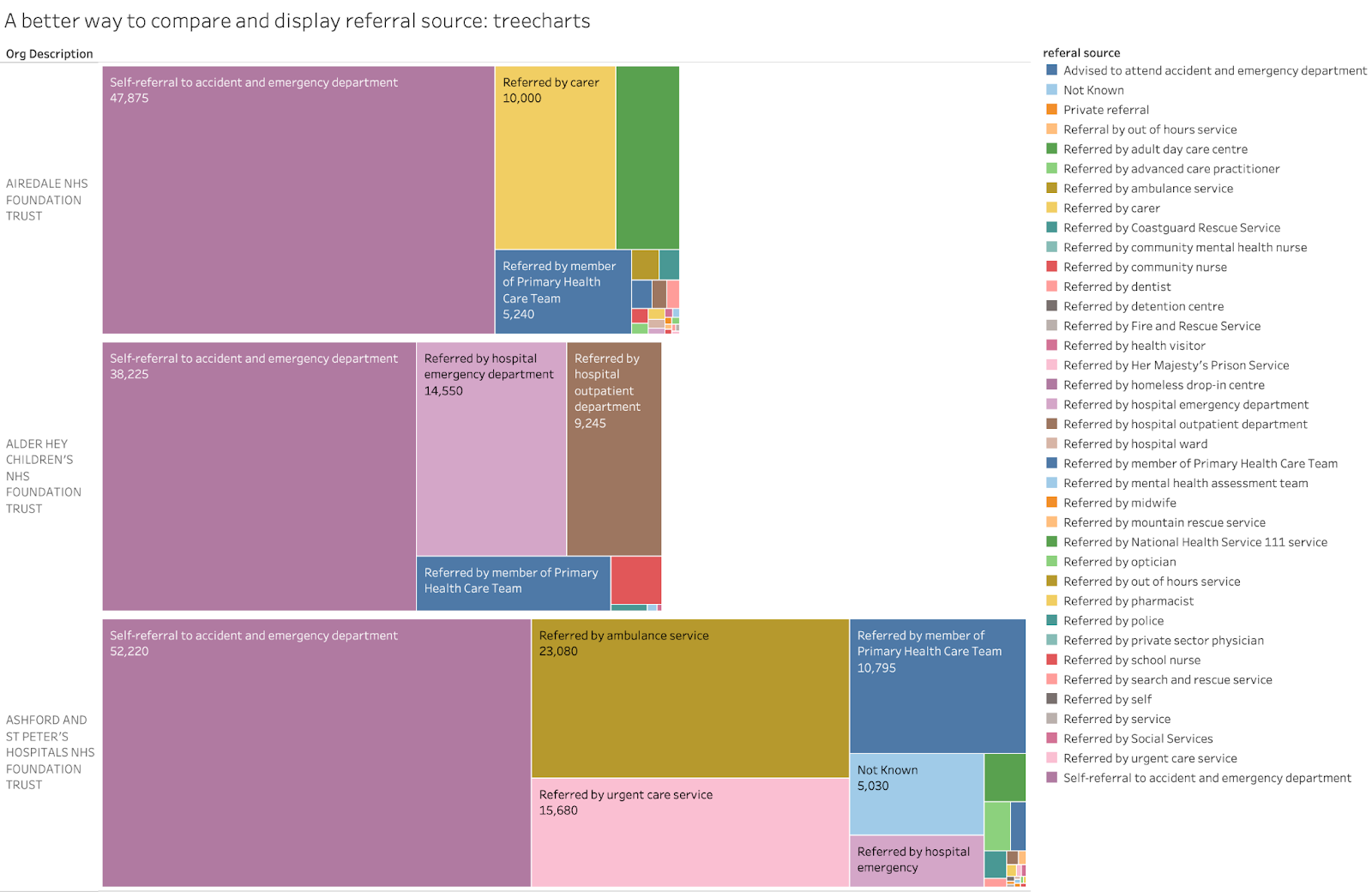
If the chart were interactive, the unreadable labels in small boxes in the treecharts could show pop-ups identifying the group (as the interactive version of the above chart does). This would minimise the loss of information because of unreadable labels.
One default chart in the Attendances section of the dataviz tool hints that the data contains a number of different classifications of attendance. But the chart is an abomination for multiple reasons. There are far too many categories and almost none of the labels are readable. But, worse, there are at least six different categories here which are unrelated to each other (e.g. deprivation, gender, ethnicity…). Of course, totalling things across independent categories gives a stupid, meaningless total (confusingly labelled "attendances") that visually dominates the chart.
The very least that should have been done to make this useful would have been to group the various metrics together to show only related items (eg deprivation status, attendance source, discharge destination, ethnicity). As it is the chart does more to obscure the rich data available than it does to visualise anything useful.

Some other charts in the pack do attempt the job of showing just one category from this data and allowing comparisons across trusts. For example there is an interactive chart that allows comparisons across trusts and to national data for the deprivation status of the attenders.
The national chart doesn't look too bad apart from basic readability and ugliness of the labels:
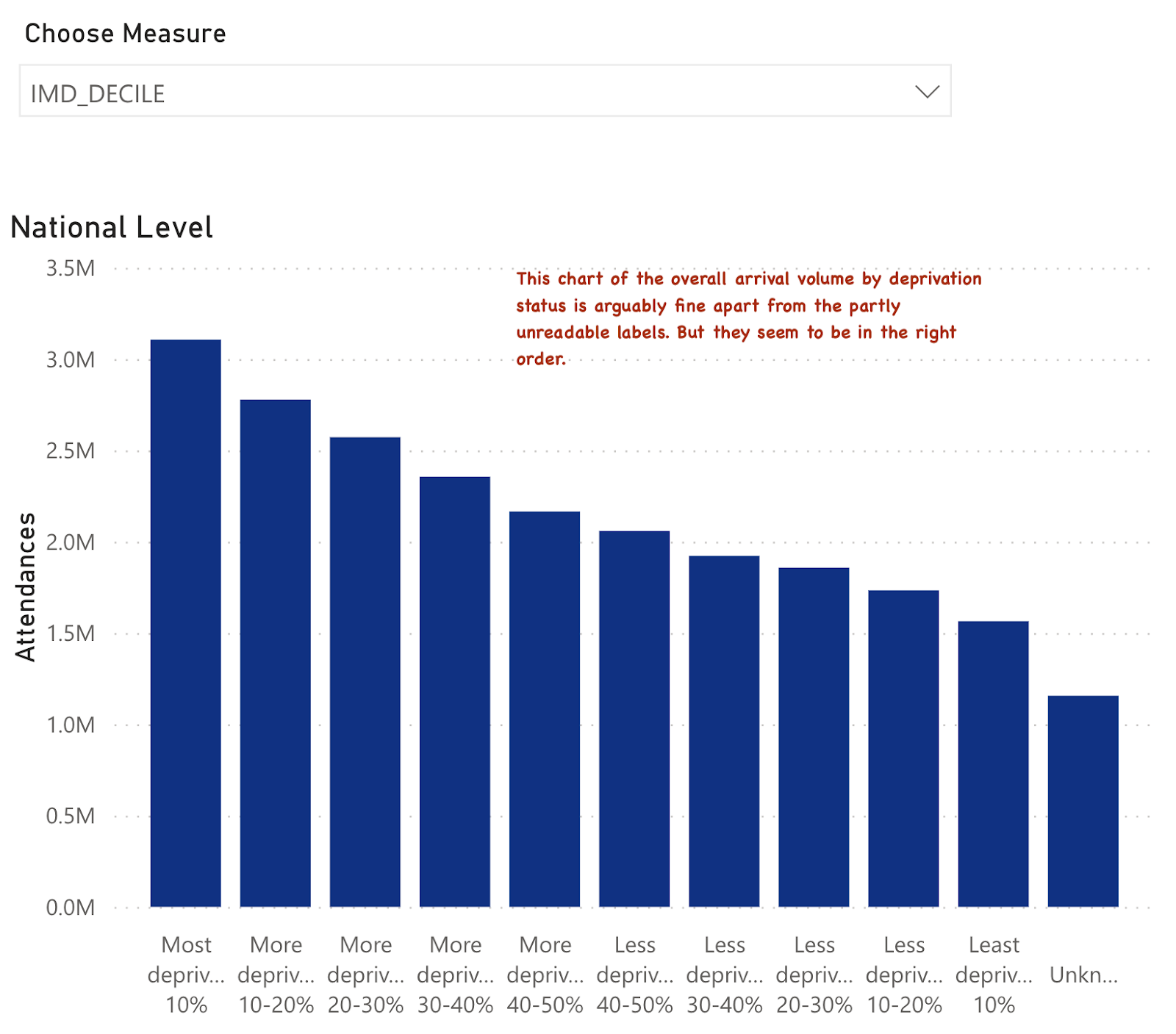
But it sits beside a chart intended to allow a comparison across multiple trusts and to the national pattern. But it looks like this:
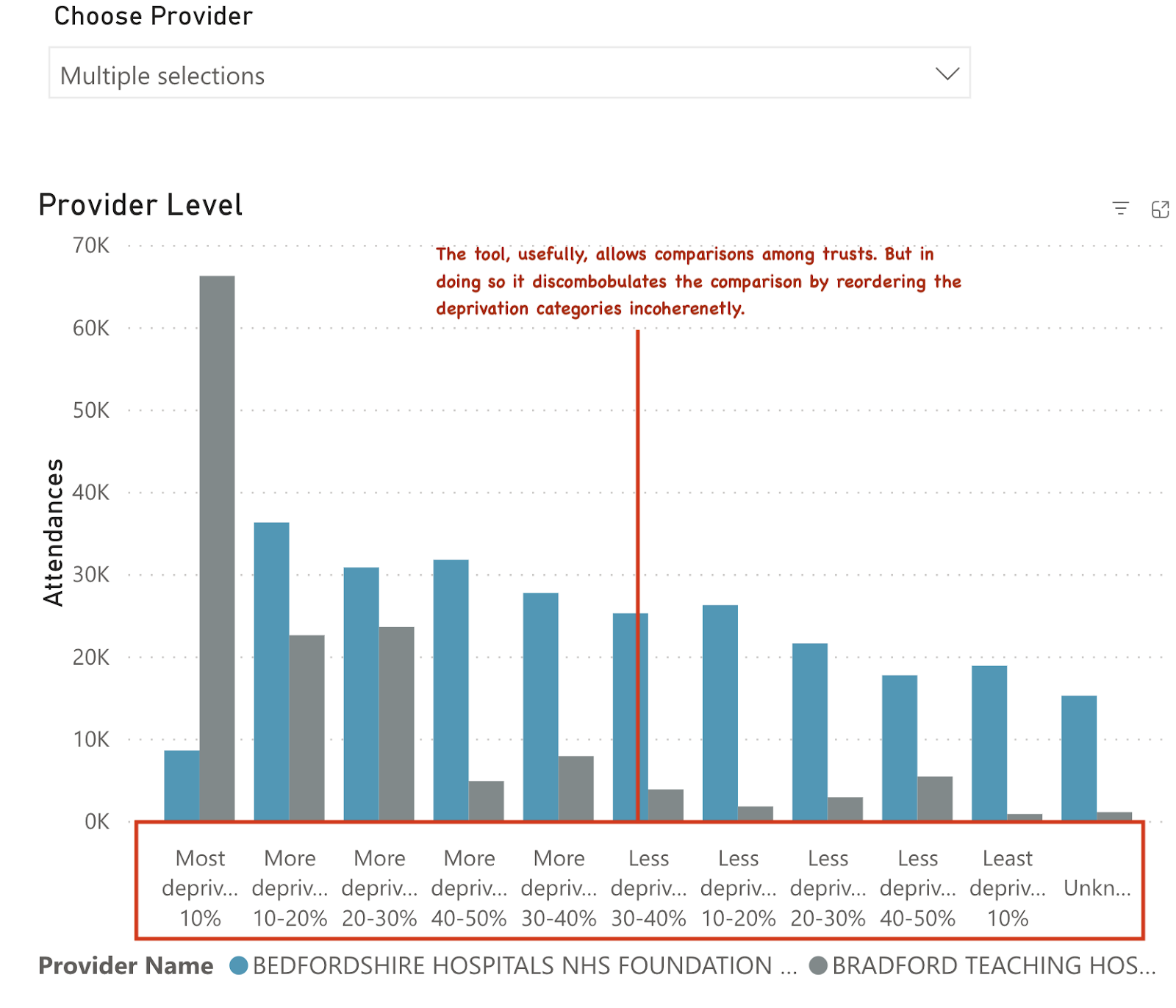
The idea of providing comparisons is good. But to make the national comparisons, the order of the deprivation categories needs to be the same. And, while a diligent user could do a comparison among several hospitals, the overall pattern of their attenders by deprivation status is obscured because the categories have been scrambled somewhat randomly.
Here is an example from the actual data that shows what could have been done to make this more useful and coherent:
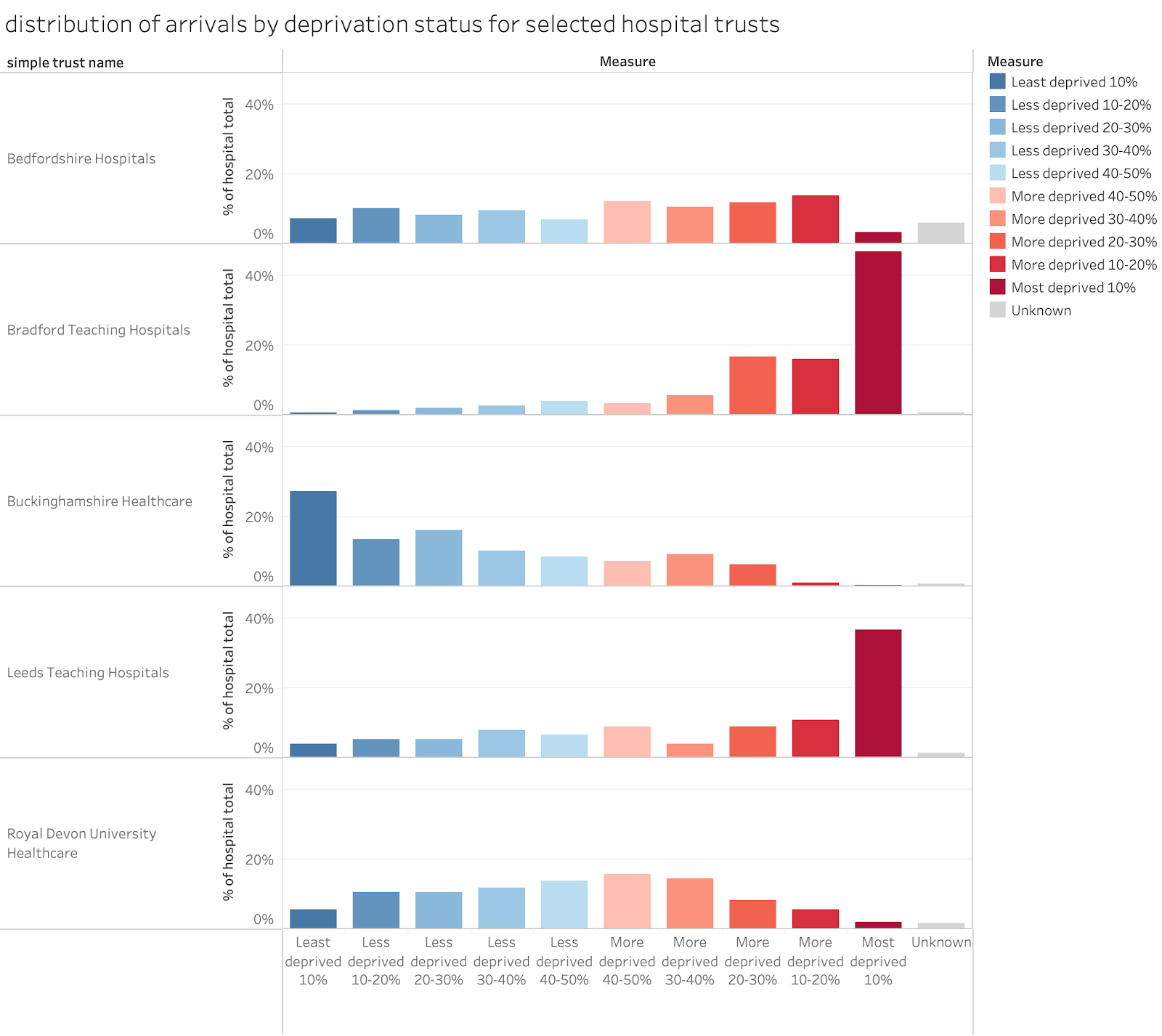
Here the comparison across hospitals is easier. A simple colour-code has been added to make visually scanning the labels unnecessary (more deprived gets deeper red, less deprived gets deeper blue). And the scale always runs in order from least to most deprived. The stark differences across the chosen hospitals in the deprivation mixes of their populations is very clear.
I could give even more examples but the ones above give a good range of illustrations of the very general issues in the NHSD visualisation tool. None of the charts have been customised in any way to make the dataviz more useful. Many end up so messy them make it impossible to make sense of the underlying data.
What general lessons can be drawn?
A general lesson for both visualisation and data structuring is very clear: it helps to know why and how the data will be used and what the best way to visualise it is.
But there are also too many examples where the structure of the data does not facilitate the sort of useful analysis that the majority of potential users might desire. For example, those who would like to analyse demographic data for linked age and gender as a standard population pyramid can’t do so as the data structure provides only gender totals but not the breakdown by age and gender.
And, for those who might want to analyse the relationship between diagnosis, investigation and treatment they will find this can’t be done as, again, the three categories are not linked. Moreover, while the diagnosis and treatment data has ~1k distinct codes (which can be useful for researchers wanting to understand the mix of problems and treatments) the move to snomSNOMED CT coding seems to make it harder to group things together to get an overview (pre ECDS procedures were coded with OPCS codes and diagnosis with ICD10 codes which are both hierarchical systems which makes grouping related things together to get a broad category to obtain an overview much easier). SNOMED might allow this but the documentation of the coding is a mess and the links to the full data dictionary are often broken in the full documentation.
This may be an unfair criticism as many researchers will use the full patient-level records where many of these problems don’t exist, but what is the point of providing an annual summary with lots of detail but no way to link it across different categories or summarise it with existing hierarchies.
And providing a tool for data visualisation is a good way to enable users to navigate the rich data. But not if the structure of the data has been ignored in choosing the method of visualising it. And most of the choices of how to present the data are extremely bad choices.
The dataviz tool looks like it was created by dropping data tables into whatever the default PowerBI choice of chart is (every chart seems to be a vertical bar chart whatever the data looks like). For some charts this is fine, but even when this a good choice of chart type, the details have often been mangled. There is no point in presenting breakdowns by age if the age categories are not in order, for example.
There is also vital information missing. Some data, as I demonstrated above, is extraordinarily useful for understanding performance. The shape of the distribution of waiting times is a good example. The data release could have presented the distribution of waiting times in detail. Instead of that we get some of the simple statistical summaries (median waiting time, mean waiting time and the 95 percentiles). These tell us something but showing the full distribution (in 15min or whole hour groups) would have been far more useful.
Final thoughts
This is a missed opportunity by NHSD. They wanted to release far more detail than usual in the report. But they have chosen which details to present poorly and have failed to consider how users might want to use the data.
And in choosing to offer an interactive visualisation they pay lip service to a good idea. But, by failing to pay the minimal attention to the basic principles of good visualisation, they have created an epic fail which obscures rather than enables a better understanding of the data. It might be used in future as a cardinal example of how to do dataviz badly.
It is fixable, though. And they have already changed some of the most egregious examples on the basis of public criticism. But the whole approach needs a complete rethink taking into account what reasonable users might want to do with the data.
There are still some people around who know which parts of the data are important and how to visualise them (some in think tanks, some in the better CSUs and some independents). Heck, I’ve been analysing and visualising A&E data for over 20 years.
NHSD could usefully consult with some of the experts to rethink the whole release and the dataviz based on it to make it far more useful.